文/诸葛ioCEO
关于爬虫内容的分享,我会分成两篇,六个部分来分享,分别是:
我们的目的是什么内容从何而来了解网络请求一些常见的限制方式尝试解决问题的思路效率问题的取舍
本文先聊聊前三个部分。
一、我们的目的是什么
一般来讲对我们而言需要抓取的是某个网站或者某个应用的内容,提取有用的价值,内容一般分为两部分,非结构化的文本,或者结构化的文本。
关于非结构化的数据
1.1 HTML文本(包含java代码)
HTML文本基本上是传统爬虫过程中最常见的,也就是大多数时候会遇到的情况,例如抓取一个网页,得到的是HTML,然后需要解析一些常见的元素,提取一些关键的信息。HTML其实理应属于结构化的文本组织,但是又因为一般我们需要的关键信息并非直接可以得到,需要进行对HTML的解析查找,甚至一些字符串操作才能得到,所以还是归类于非结构化的数据处理中。
常见解析方式如下:
CSS选择器
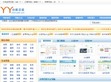
现在的网页样式比较多,所以一般的网页都会有一些CSS的定位,例如class,id等等,或者我们根据常见的节点路径进行定位,例如腾讯首页的财经部分:


这里id就为finance,我们用css选择器,就是"#finance"就得到了财经这一块区域的html,同理,可以根据特定的css选择器可以获取其他的内容。
XPATH
XPATH是一种页面元素的路径选择方法,利用chrome可以快速得到,如:


copy XPATH 就能得到——//*[@id="finance"]
正则表达式
正则表达式,用标准正则解析,一般会把HTML当做普通文本,用指定格式匹配当相关文本,适合小片段文本,或者某一串字符,或者HTML包含java的代码,无法用CSS选择器或者XPATH。
字符串分隔
同正则表达式,更为偷懒的方法,不建议使用。
1.2 一段文本
例如一篇文章,或者一句话,我们的初衷是提取有效信息,所以如果是滞后处理,可以直接存储,如果是需要实时提取有用信息,常见的处理方式如下:
分词
根据抓取的网站类型,使用不同词库,进行基本的分词,然后变成词频统计,类似于向量的表示,词为方向,词频为长度。
NLP
自然语言处理,进行语义分析,用结果表示,例如正负面等。
关于结构化的数据结构化的数据是最好处理,一般都是类似JSON格式的字符串,直接解析JSON数据就可以了,提取JSON的关键字段即可
二、内容从何而来
过去我们常需要获取的内容主要来源于网页,一般来讲,我们决定进行抓取的时候,都是网页上可看到的内容,但是随着这几年移动互联网的发展,我们也发现越来越多的内容会来源于移动app,所以爬虫就不止局限于一定要抓取解析网页,还有就是模拟移动app的网络请求进行抓取,所以这一部分我会分两部分进行说明。
1 网页内容
网页内容一般就是指我们最终在网页上看到的内容,但是这个过程其实并不是网页的代码里面直接包含内容这么简单,所以对于很多新人而言,会遇到很多问题,比如:
明明在页面用Chrome或者Firefox进行审查元素时能看到某个HTML标签下包含内容,但是抓取的时候为空。
很多内容一定要在页面上点击某个按钮或者进行某个交互操作才能显示出来。
所以对于很多新人的做法是用某个语言别人模拟浏览器操作的库,其实就是调用本地浏览器或者是包含了一些执行java的引擎来进行模拟操作抓取数据,但是这种做法显然对于想要大量抓取数据的情况下是效率非常低下,并且对于技术人员本身而言也相当于在用一个盒子,那么对于这些内容到底是怎么显示在网页上的呢?主要分为以下几种情况:
注:相关网站建设技巧阅读请移步到建站教程频道。